Two weeks ago, the Society for Personality and Social Psychology (SPSP) held its annual meeting in Austin, TX. I tried to get there myself, as I had been invited to give a talk on the measurement of oxytocin in social science research as part of the “Social Neuroendocrinology” pre-conference. However, some things were brewing on the home front that kept me in Miami. Undeterred, the pre-conference organizers arranged for me to give my talk via Skype, which worked out reasonably well.
In this essay, I’ve turned some of that talk into the second installment in my “The Trouble with Oxytocin” series (the first installment is here). It’s a bit wonkish, focusing as it does on the importance of a bioanalytical technique called extraction, but it’s an important topic nonetheless. Many of the social scientists who are studying oxytocin have decided that they can skip this step entirely. As a result of their decision to take this shortcut, it’s quite possible that many scientific claims about the personality traits, emotions, and relationship factors that influence circulating oxytocin levels are—how to put this diplomatically?—without adequate basis in fact. I’ll substantiate this claim anon, but first, a bit of nomenclature.
A Bit of Nomenclature
Applied researchers generally measure oxytocin in bodily fluids by immunoassay—a technique so ingenious that the scientists who developed it received a Nobel Prize in 1977. Simplifying greatly, to develop an immunoassay for Substance X, you inject animals (probably rabbits) with Substance X and wait for the animal(s) to produce an immune reaction. To the extent that one of the antibodies an animal produces in response to Substance X is sensitive to Substance X, but not to other substances that can masquerade as Substance X, you may be in a position to conclude that you have successfully produced a “Substance X antibody.” With that antibody in hand, you’ve got the most important ingredient for developing an immunoassay.
Antibodies can be used to make several types of immunoassays, but two types are prominent in the oxytocin field: Radioimmunoassays (RIA) and Enzyme-Linked Immunosorbent Assays (ELISA, or EIA). Both methods are widely accepted (although ELISAs don’t require the analysts to handle radiation—a benefit to be sure). I wanted to familiarize you with these terms here at the outset only because I don’t want my toggling back and forth between them to distract you. The focal issue for our purposes here is the issue of extraction.
To Be Exact, You Must Extract
Extraction is a set of preliminary processes an analyst can use to separate Substance X from other substances in a sample of (for instance) blood plasma that might interfere with the immunoassay’s ability to quantify precisely how much Substance X is in the sample. I’m going to skip the details, but you can read up here. Antibodies can bind to all sorts of substances that are not Substance X (for example, proteins, other peptides, or their degradation products) if you’re not careful to remove that other stuff first. More relevant for our purposes here, researchers have known for a really long time that a failure to extract before conducting immunoassays for plasma oxytocin will result in profound overestimates of how much oxytocin is actually in the sample.
This is not some well-kept industry secret. The manufacturers of some of the more widely used commercial ELISAs have been admonishing the users of their assays to extract samples since at least 2007. Below is a snip from an instruction manual bearing a 2006 copyright. (The admonition gets repeated in this 2013-copyright instruction manual also):

What the manufacturers are showing here (see the two columns of data on the left) is that when they performed their oxytocin assay on a sample of human blood plasma without performing an extraction step, they read off an oxytocin concentration of 2,761 pg/ml (picograms [10-12 grams] per milliliter). When they performed the extraction step on the same sample, they got a value of 3.4 pg/ml—three orders of magnitude smaller. Plain English translation: “There are some substances in human blood plasma that fool our antibody into believing they’re oxytocin molecules. You’d better get rid of those imposters before you run our assay on your sample. After you do that, we think you’ll be OK.” Keep this value of 3.4 pg/ml in mind. As I’ll show you below, it’s the sort of value, more or less, that one ought to be expecting from assays that actually measure oxytocin.
Like I say, the need for extraction is no secret. Basic biological researchers who study oxytocin have been extracting their samples since The Waltons had a prime-time slot on CBS. But extraction takes a lot of time, so it is expensive. Perhaps this is why a team of researchers started to skip the extraction step in the early 2000s.[1] In no time at all, other social scientists were following in their footsteps, and with that, a Pandora’s box was opened. Most social scientists just stopped extracting, often citing the originators of this custom to justify their choice.
In what follows, I’ll chronicle what happened to the social science literature on oxytocin as a result of this fateful methodological choice. Table 1, below, is from a paper that Armando Mendez, Pat Churchland, and I published last year.[2] It illustrates the typical oxytocin values one can expect to see in samples of extracted plasma measured by radioimmunoassay versus the values one can expect to see when using one of the commercial ELISAs on raw (i.e., unextracted) plasma.
 From McCullough, Churchland, and Mendez (2013)
From McCullough, Churchland, and Mendez (2013)
A few things stand out in Table 1. First, when you measure oxytocin in blood plasma using RIA on extracted samples, you typically find that healthy, non-pregnant women and men have oxytocin levels of somewhere between 0 and 10 picograms per milliliter of blood plasma. This is consistent with that value of 3.4 pg/ml that I suggested you keep in mind from the 2006 instructions that came with that assay kit.
Below are some values that Ben Tabak, our neuroscience/biochemistry colleagues, and I obtained on 35 women whose oxytocin we measured in five different samples of plasma. Mean values were in the 1-2 picogram range.[3]
 Adapted from Tabak et al., (2011)
Adapted from Tabak et al., (2011)
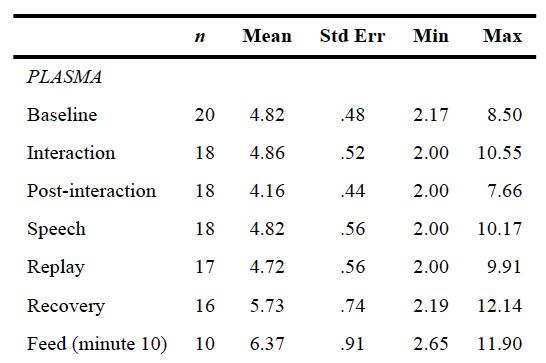
The Tabak et al. (2011) sample was small. We had oxytocin values for only a few dozen women, so I won’t be offended if you don’t want to place too much trust in them, but here are some values that Tim Smith and his colleagues obtained with an RIA on extracted samples from 180 male-female couples: Again, their mean values hovered around 1-2 picograms per milliliter. [4]
 From Smith et al., 2013
From Smith et al., 2013
So this is very reassuring. The values that we got, and the values that Smith and his colleagues got, are very consistent with the 1-10 pg/ml range that we’ve come to expect over the past 35 years.
From McCullough, Churchland, and Mendez (2013)
But now take a look the right side of Table 1 above to see what happens when you assay plasma for oxytocin using commercial ELISAs without extraction. It doesn’t matter whether you’re studying healthy non-pregnant women, healthy non-pregnant men, pregnant women, or new mothers: You’re going to get mean oxytocin values in the 200-400 pg/ml range, that is, values that are 100 to 200 times higher than what you get with RIAs on extracted samples.
Consider, for instance, the data below, which come from this paper, which the authors accurately described in the abstract as “[u]tilizing the largest sample of plasma OT to date (N = 473).” They found a mean value for men of approximately 400 pg/ml and a mean value for women of around 359 pg/ml.[5]
 From Weisman et al. (2013)
From Weisman et al. (2013)
Mean values of 200, 300, and 400 pg/ml for oxytocin in unextracted plasma are not exceptions to an otherwise orderly corpus of findings. They are what you should expect to find if you perform an oxytocin assay without extraction. For instance, the data below, from this paper show the sorts of oxytocin values you can expect to find in the plasma of pregnant and recently pregnant women when you use ELISA on raw plasma:[6]
 From Feldman et al. (2007)
From Feldman et al. (2007)
The values above are measured in picomolars rather than in pg/ml, but oxytocin has a molecular mass of 1007 Daltons, so by sheer coincidence one picomolar of oxytocin is roughly equivalent to one pg/ml. In other words, these authors also got mean values for oxytocin using an ELISA on raw plasma that are way too high—and look at the upper end of those ranges—3,648 pg/ml! There’s just no good reason for believing that there could be 300 picograms of OT—much less 3,648—in a milliliter of blood plasma.
Why are these ELISAs giving such high values? There’s nothing wrong in principle with using an ELISA to measure OT in plasma, even though some of the commercial assays have used antibodies whose sensitivity and specificity is far from ideal. (This is an extremely important issue, by the way, but not the one to tackle here.) Instead, the predominant reason why researchers are getting such wacky values from these ELISAs is that they’re skipping the extraction step.
How do I know? Because I know what happens if you do extract your samples before you assay them via ELISA. Our research group found that when you extract your samples before you analyze them with a certain commercial ELISA kit, the mean values drop from somewhere around 358 pg/ml to somewhere around 1.8 pg/ml—just as you’d expect, given the admonitions in the manufacturer’s instructions.[7] And here are some extracted values that Karen Grewen and her colleagues got for 20 healthy breastfeeding mothers when they used the same ELISA that gave Weisman et al. those values in the 300-400 pg/ml range for raw plasma.[8] ELISAs can give plausible values if you extract first.
 From Grewen, Davenport, and Light (2010)
From Grewen, Davenport, and Light (2010)
Estimating OT from Unextracted Samples: Is There Any Signal Amidst the Noise?
Of course, none of this would matter very much if there were some way to statistically transform the OT values you obtain from unextracted plasma into the values you would have obtained from extracted plasma, but that doesn’t seem to be the case: The evidence currently available suggests that the values from the two methods are, quite possibly, uncorrelated.
We looked at this issue in our 2011 paper.[7] We had 39 plasma samples, which we analyzed with one of the most widely used commercial ELISAs, both before and after extraction. The correlation coefficients ranged from .09 to -.14, depending on distributional assumptions. Kelly Robinson and her colleagues just came to the same conclusion with their own data—52 samples of blood plasma from seals.[9] In fairness, I have to acknowledge another study that revealed a very high correlation between the oxytocin values derived from extracted samples versus those obtained from unextracted samples (0.89), but that study was based on very little data (11 samples of blood serum, rather than plasma, from Rhesus monkeys), so it would be a mistake to give it too much weight.[10]
Conclusion
So, what shall we conclude about oxytocin assays on unextracted plasma, given the data we have to go on at this point? Well, on the plus side, raw plasma is cheaper and quicker to assay than extracted plasma. Nobody disputes that. On the minus side, if you don’t extract those samples before you assay them, you apparently convert those ingenious oxytocin assays into random number generators, and there are cheaper ways to generate random numbers.
For ten years, many social scientists who study oxytocin have been side-stepping an expensive but evidently crucial extraction step. If you’ve come to believe that the trust of a stranger, or sharing a secret, or sensitive parenting, or mother-infant bonding, or your mental health, can influence (or is influenced by) how much oxytocin is coursing through your veins, you might want to take a second look. Chances are, those findings came from studies that used immunoassays on unextracted plasma (it’s easy to know for sure: just check the papers’ Method sections), and if so, there’s little compelling reason to think the results are accurate.
Now, if any researchers out there have data that can prove that we should be taking the results from immunoassays on unextracted samples at face value, they would do the field a great favor to make those results public, and at that point I will happily concede that all my worrying has been for nought. Even better, perhaps someone could conduct a large, pre-registered study on the correlation of OT values from extracted versus raw plasma. Pre-registration is easy (for example, here), and would increase the inferential value of such a study immensely. In any case, more data on this topic would be most welcome. I, for one, would love to know whether we should be taking the results of studies on raw plasma seriously, or whether we’d be better off by dragging them into the recycle folder.
References
1. Kramer, K.M., et al., Sex and species differences in plasma oxytocin using an enzyme immunoassay. Canadian Journal of Zoology, 2004. 82: p. 1194-1200.
2. McCullough, M.E., P.S. Churchland, and A.J. Mendez, Problems with measuring peripheral oxytocin: Can the data on oxytocin and human behavior be trusted? Neuroscience and Biobehavioral Reviews, 2013. 37: p. 1485-1492.
3. Tabak, B.A., et al., Oxytocin indexes relational distress following interpersonal harms in women. Psychoneuroendocrinology, 2011. 36: p. 115-122.
4. Smith, T.W., et al., Effects of couple interactions and relationship quality on plasma oxytocin and cardiovascular reactivity: Empirical findings and methodological considerations. International Journal of Psychphysiology, 2013. 88: p. 271-281.
5. Weisman, O., et al., Plasma oxytocin distributions in a large cohort of women and men and their gender-specific associations with anxiety. Psychoneuroendocrinology, 2013. 38: p. 694-701.
6. Feldman, R., et al., Evidence for a neuroendocrinological foundation of human affiliation: Plasma oxytocin levels across pregnancy and the postpartum period predict mother-infant bonding. Psychological Science, 2007. 18: p. 965-970.
7. Szeto, A., et al., Evaluation of enzyme immunoassay and radioimmunoassay methods for the measurement of plasma oxytocin. Psychosomatic Medicine, 2011. 73: p. 393-400.
8. Grewen, K.M., R.E. Davenport, and K.C. Light, An investigation of plasma and salivary oxytocin responses in breast- and formula-feeding mothers of infants. Psychophysiology, 2010. 47: p. 625-632.
9. Robinson, K.J., et al., Validation of an enzyme-linked immunoassay (ELISA) for plasma oxytocin in a novel mammal species reveals potential errors induced by sampling procedure. Journal of Neuroscience Methods, in press.
10. Michopoulos, V., et al., Estradiol effects on behavior and serum oxytocin are modified by social status and polymorphisms in the serotonin transporter gene in female rhesus monkeys. Hormones and Behavior, 2011. 58: p. 528-535.















{kind=link}